No, had tried that, as the commit hinted to being related to histogram stuff.
Ah no, wait. The histogram does have its own median field, that contains a value. Had overlooked that.
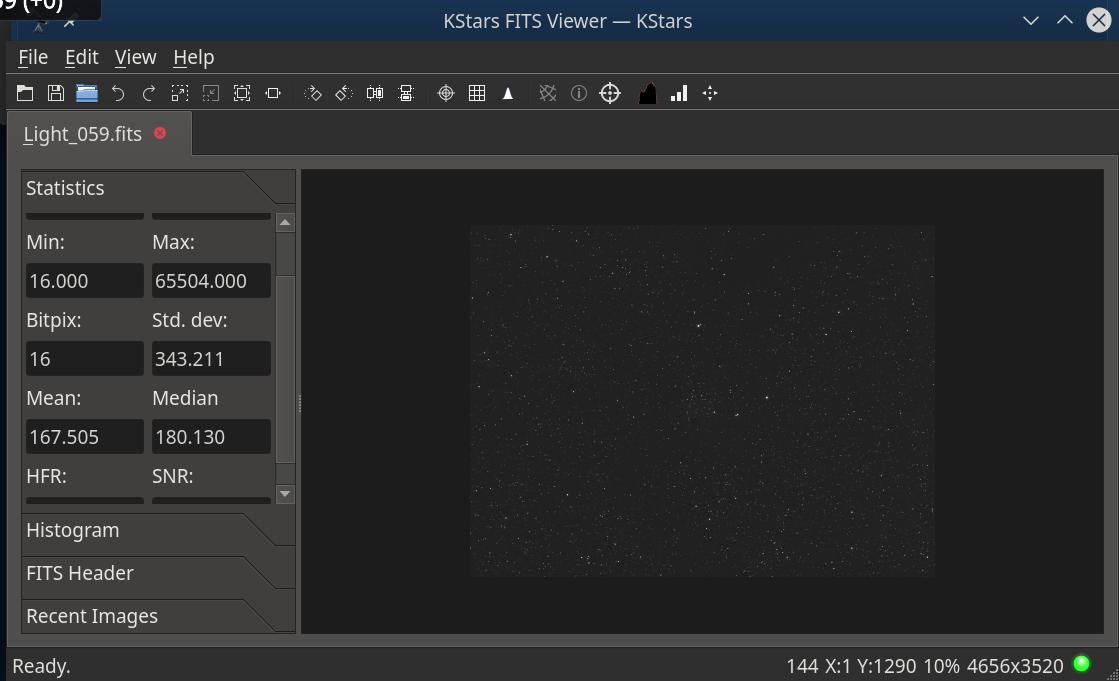
But I do get the same (high) value of 180 for the median with and without that commit.
Playing around with it a bit more, median really behaves strange. It changes substantially when the image is clipped. E.g., load an image, activate histogram. I get mean 167.5, median 180.1. The limit slider (only R, it's a monochrome image) is at 16 and 65504. Change the lower clip to 17 and click 'Apply', and median changes to 181.1! mean stays unchanged. Clipping an array will never change the median, unless the low clip is higher than the unclipped median (or the high one lower). Also, for an (u)int array, it should not be a fractional number.
IDL> help,p
P UINT = Array[4656, 3520]
IDL> print,avg(p),avg(p>20000),avg(p>20000<22500)
22400.446 22402.729 22186.562
IDL> print,median(p),median(p>20000),median(p>20000<22500)
22480.0 22480.0 22480.0